The Central Dogma of Molecular Biology
An interactive study guide for high school biology students
Introduction to the Central Dogma
The Central Dogma of Molecular Biology describes the flow of genetic information within a biological system. It explains how the information in DNA is converted into RNA through transcription, and how RNA is then used to produce proteins through translation.
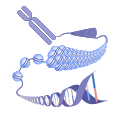
The structure of DNA, the genetic blueprint of life.
This fundamental principle, first articulated by Francis Crick in 1958, forms the backbone of our understanding of how genetic information is stored, transferred, and expressed in living organisms. The Central Dogma can be summarized as:
DNA → RNA → Protein
Genetic information flows from DNA to RNA through transcription, and from RNA to protein through translation.
In this study guide, we will explore each component of the Central Dogma in detail, examining the structures and functions of DNA and RNA, the processes of transcription and translation, and how mutations in DNA can lead to genetic diseases.
DNA: The Genetic Blueprint
Deoxyribonucleic acid (DNA) is a molecule that carries the genetic instructions used in the growth, development, functioning, and reproduction of all known living organisms.
The double helix structure of DNA, showing the complementary base pairing.
Structure of DNA
DNA consists of two long polymers of nucleotides twisted around each other to form a double helix. Each nucleotide contains:
- A phosphate group
- A sugar (deoxyribose)
- A nitrogenous base (adenine, thymine, guanine, or cytosine)
The two strands of DNA are held together by hydrogen bonds between complementary base pairs: adenine (A) pairs with thymine (T), and guanine (G) pairs with cytosine (C).
Function of DNA
The primary function of DNA is to store genetic information. The sequence of nucleotides in DNA encodes the instructions for building and maintaining an organism. These instructions are organized into units called genes, which specify the sequence of amino acids in proteins.
Checkpoint: DNA Structure and Function
RNA: The Messenger
Ribonucleic acid (RNA) is a polymeric molecule essential in various biological roles in coding, decoding, regulation, and expression of genes.
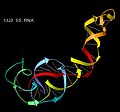
The structure of RNA, showing its single-stranded nature.
Structure of RNA
Like DNA, RNA is made up of nucleotides. However, RNA differs from DNA in several ways:
- RNA is typically single-stranded, while DNA is double-stranded
- RNA contains the sugar ribose instead of deoxyribose
- RNA uses the base uracil (U) instead of thymine (T)
Types of RNA
There are several types of RNA, each with a specific role in protein synthesis:
- Messenger RNA (mRNA): Carries genetic information from DNA to the ribosome
- Transfer RNA (tRNA): Brings amino acids to the ribosome during protein synthesis
- Ribosomal RNA (rRNA): Forms part of the structure of ribosomes
Checkpoint: RNA Structure and Function
Transcription: DNA to RNA
Transcription is the process by which the information in a strand of DNA is copied into a new molecule of messenger RNA (mRNA).
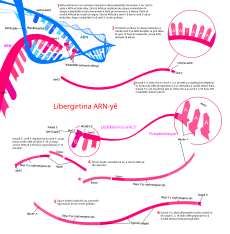
The process of transcription, showing RNA polymerase synthesizing an RNA strand from a DNA template.
Steps of Transcription
- Initiation: RNA polymerase binds to the promoter region of DNA
- Elongation: RNA polymerase moves along the DNA, synthesizing an RNA strand complementary to the DNA template strand
- Termination: RNA polymerase reaches a termination signal and releases the newly synthesized RNA
RNA Processing in Eukaryotes
In eukaryotes, the newly synthesized RNA (pre-mRNA) undergoes several modifications before leaving the nucleus:
- 5' Capping: Addition of a modified guanine nucleotide to the 5' end
- Splicing: Removal of introns (non-coding regions) and joining of exons (coding regions)
- 3' Polyadenylation: Addition of a poly-A tail to the 3' end
Checkpoint: Transcription Process
Translation: RNA to Protein
Translation is the process by which the genetic code carried by mRNA is decoded to produce a specific sequence of amino acids in a polypeptide chain.

The process of translation, showing the ribosome synthesizing a protein using mRNA as a template.
Steps of Translation
- Initiation: The ribosome assembles around the mRNA and the first tRNA
- Elongation: The ribosome moves along the mRNA, adding amino acids to the growing polypeptide chain
- Termination: The ribosome reaches a stop codon and releases the completed polypeptide chain
The Genetic Code
The genetic code is the set of rules by which information encoded in genetic material (DNA or RNA) is translated into proteins. It consists of codons, which are three-nucleotide sequences that specify a particular amino acid or a stop signal.
The genetic code has several important features:
- It is universal (with minor exceptions)
- It is degenerate (multiple codons can specify the same amino acid)
- It is non-overlapping (each nucleotide is part of only one codon)
- It has start and stop codons
Checkpoint: Translation Process
Mutations and Genetic Diseases
Mutations are changes in the nucleotide sequence of DNA. They can occur spontaneously or be caused by environmental factors such as radiation or chemicals.
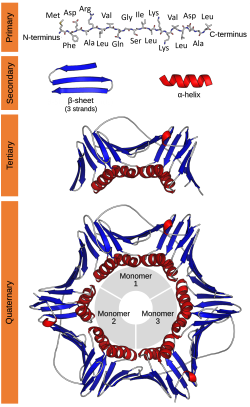
Protein structure showing primary, secondary, and tertiary levels of organization.
Types of Mutations
- Point Mutations: Substitution of one nucleotide for another
- Insertions: Addition of one or more nucleotides
- Deletions: Removal of one or more nucleotides
- Frameshift Mutations: Insertions or deletions that alter the reading frame
Sickle Cell Anemia: A Case Study
Sickle cell anemia is a genetic disease caused by a point mutation in the gene that codes for the beta-globin chain of hemoglobin.
Normal Hemoglobin
The normal gene sequence codes for glutamic acid at position 6 of the beta-globin chain.
DNA: CTT
Amino Acid: Glutamic Acid
Result: Normal, flexible red blood cells that can easily pass through blood vessels
Sickle Cell Hemoglobin
A point mutation changes the codon to one that codes for valine instead.
DNA: CAT
Amino Acid: Valine
Result: Abnormal hemoglobin that causes red blood cells to become sickle-shaped, leading to blockages in blood vessels
This single amino acid change dramatically alters the structure and function of hemoglobin, leading to the symptoms of sickle cell anemia.
Checkpoint: Mutations and Genetic Diseases
Matching Exercises
Test your understanding of the Central Dogma by matching the following terms with their definitions.